降って湧いたような衆院選が終わりました。期間中お届けした紙面は読者の皆さんのお役に立てたでしょうか。今回の選挙報道における校閲作業の風景をほんの少しご紹介します。
衆院が解散されることが確実とみられるようになった11月中旬、校閲グループでも専従班を中心に本格的な準備を始めました。
まず、立候補が予想される1000人余について、各支局が入力した情報を点検。氏名、年齢、当選回数、経歴などを調べ、誤りを正したり、肩書の略し方などがバラバラにならないよう基準に合わせたりしていきます。これは候補者や当選者の一覧、名鑑として掲載されるだけでなく、公示や投開票時の1面に組み込む人数表の自動計算、またさまざまな分析記事のためのデータ集計にも反映されるもので、すべてのチェック作業の基礎といえます。ちなみに今回の選挙では、無所属の候補1人を自民党が追加公認したと投開票日になって発表したため、自動集計の結果を手動で修正することになり、公示時と開票の紙面で基礎資料に違いが生じました。
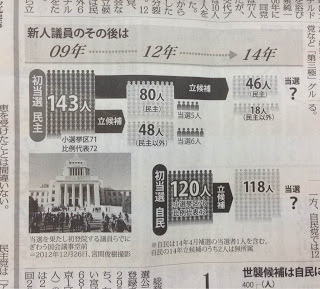
さて、出稿部や編集部門で紙面案が具体化してくると、分析記事につける図表類のチェックに追われます。過去の衆院選の投票率や立候補者数の推移といった単純なものもあれば、グラフと年表を組み合わせた凝った作りのものもあります。今回印象深かったのは、近年の衆院選の「新人議員のその後」をまとめた図(写真、12月3日付朝刊)。地味な割に手間がかかりました。2009年に民主党で初当選した143人のうち、次の12年も民主党から立候補した人数、民主以外で出馬した人数、さらにそれぞれの当落……と、ここまでは過去の紙面をもとに手で数えて誤りを正せたものの、締め切り時間が迫り、今回立候補分までは数える余裕がありません。そこで助けてくれたのが、表計算ソフトを使ったデータ処理チームでした。
校閲では、選挙報道用のシステムが機能しなくなる事態に備え、並行してデータ管理をしており、それが細かい数字を使った分析記事の点検に力を発揮しています。例えば「12年に民主党と第三極が競合した選挙区のうち、民主党候補と第三極候補の得票の合計が自民党候補を上回ったところが109選挙区あった」「この中で今回68選挙区が共闘型に変わり、野党が12勝した」といった、根性だけでは対処しきれない原稿にも短時間でOKを出せるようになっているのです。
もちろん、機械にさえ任せておけば万全ということではありません。データ処理チームの若手も思わず首をひねった場面がありました。「党派別の得票数の表に入った数字が、手元のデータと合わない」。ほどなく自民党の金子恵美(めぐみ)氏と民主党の金子恵美(えみ)氏の同じ漢字の2人をコンピューターが混同したためと突き止め、表が正しいことを確認できました。他にも、名前に俗字や異体字の問題があるときは正確に処理できないことがあり、注意を要します。
機械にだまされず賢くデータ処理をしてくれたメンバー、その元データを一つ一つ根気強く点検したメンバー。印象的だった場面をつないで、コンピューターとのほどよい付き合い方が見えてきた、などとまとめては強引すぎるでしょうが、今回の選挙そのものの意義はさておき、これらの経験は校閲の仕事について考える材料として十分に意義深いものでした。
【宮城理志】